Introduction to Puppet
Welcome to the open source Puppet documentation!
This introduction is intended for new users to Puppet. We go over what Puppet is, what problems it solves, and the concepts and practices that are key to being successful with Puppet.
What is Puppet?
Puppet is a tool that helps you manage and automate the configuration of servers.
When you use Puppet, you define the desired state of the systems in your infrastructure that you want to manage. You do this by writing infrastructure code in Puppet's Domain-Specific Language (DSL) — Puppet Code — which you can use with a wide array of devices and operating systems. Puppet code is declarative, which means that you describe the desired state of your systems, not the steps needed to get there. Puppet then automates the process of getting these systems into that state and keeping them there. Puppet does this through Puppet primary server and a Puppet agent. The Puppet primary server is the server that stores the code that defines your desired state. The Puppet agent translates your code into commands and then executes it on the systems you specify, in what is called a Puppet run.
The diagram below shows how the server-agent architecture of a Puppet run works.
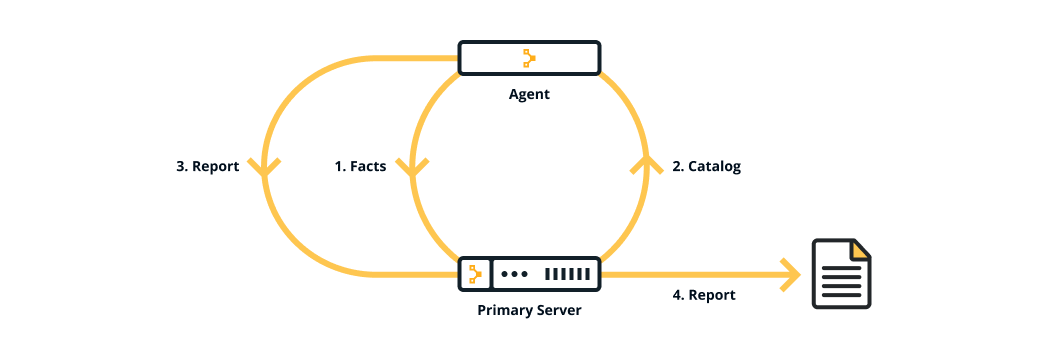
The primary server and the agent are part of the Puppet platform, which is described in The Puppet platform — along with facts, catalogs and reports.
Why use Puppet desired state management?
There are many benefits to implementing a declarative configuration tool like Puppet into your environment — most notably consistency and automation.
- Consistency. Troubleshooting problems with servers is a time-consuming and manually intensive process. Without configuration management, you are unable to make assumptions about your infrastructure — such as which version of Apache you have or whether your colleague configured the machine to follow all the manual steps correctly. But when you use configuration management, you are able to validate that Puppet applied the desired state you wanted. You can then assume that state has been applied, helping you to identify why your model failed and what was incomplete, and saving you valuable time in the process. Most importantly, once you figure it out, you can add the missing part to your model and ensure that you never have to deal with that same problem again.
- Automation. When you manage a set of servers in your infrastructure, you want to keep them in a certain state. If you only have to manage homogeneous 10 servers, you can do so with a script or by manually going into each server. In this case, a tool like Puppet may not provide much extra value. But if you have 100 or 1,000 servers, a mixed environment, or you have plans to scale your infrastructure in the future, it is difficult to do this manually. This is where Puppet can help you — to save you time and money, to scale effectively, and to do so securely.
Check out the following video of how a DevOps engineer uses Puppet:
Key concepts behind Puppet
Using Puppet is not just about the tool, but also about a different culture and a way of working. The following concepts and practices are key to using and being successful with Puppet.
Infrastructure-as-code
Puppet is built on the concept of infrastructure-as-code, which is the practice of treating infrastructure as if it were code. This concept is the foundation of DevOps — the practice of combining software development and operations. Treating infrastructure as code means that system administrators adopt practices that are traditionally associated with software developers, such as version control, peer review, automated testing, and continuous delivery. These practices that test code are effectively testing your infrastructure. When you get further along in your automation journey, you can choose to write your own unit and acceptance tests — these validate that your code, your infrastructure changes, do as you expect. To learn more about infrastructure-as-code and how it applies to Puppet, see our blog What is infrastructure as code?.
Idempotency
A key feature of Puppet is idempotency — the ability to repeatedly apply code to guarantee a desired state on a system, with the assurance that you will get the same result every time. Idempotency is what allows Puppet to run continuously. It ensures that the state of the infrastructure always matches the desired state. If a system state changes from what you describe, Puppet will bring it back to where it is meant to be. It also means that if you make a change to your desired state, your entire infrastructure automatically updates to match. To learn more about idempotency, see our Understanding idempotency documentation.
Agile methodology
When adopting a tool like Puppet, you will be more successful with an agile methodology in mind — working in incremental units of work and reusing code. Trying to do too much at once is a common pitfall. The more familiar you get with Puppet, the more you can scale, and the more you get used to agile methodology, the more you can democratize work. When you share a common methodology, a common pipeline, and a common language (the Puppet language) with your colleagues, your organization becomes more efficient at getting changes deployed quickly and safely.
Git and version control
Git is a version control system that tracks changes in code. While version control is not required to use Puppet, it is highly recommended that you store your Puppet code in a Git repository. Git is the industry standard for version control, and using it will help your team gain the benefits of the DevOps and agile methodologies
When you develop and store your Puppet code in a Git repository, you will likely have multiple branches — feature branches for developing and testing code and a production branch for releasing code. You test all of your code on a feature branch before you merge it to the production branch. This process, known as Git flow, allows you to test, track, and share code, making it easier to collaborate with colleagues. For example, if someone on your team wants to make a change to an application's firewall requirements, they can create a pull request that shows their proposed changes to the existing code, which everyone on your team can review before it gets pushed to production. This process leaves far less room for errors that could cause an outage. For more information on version control, see the GitHub guides Git flow and What is version control?.
The Puppet platform
Puppet is made up of several packages. Together these
are called the Puppet platform, which is what you use to manage, store and run your Puppet
code. These packages include puppetserver, puppetdb, and
puppet-agent — which includes Facter and
Hiera.
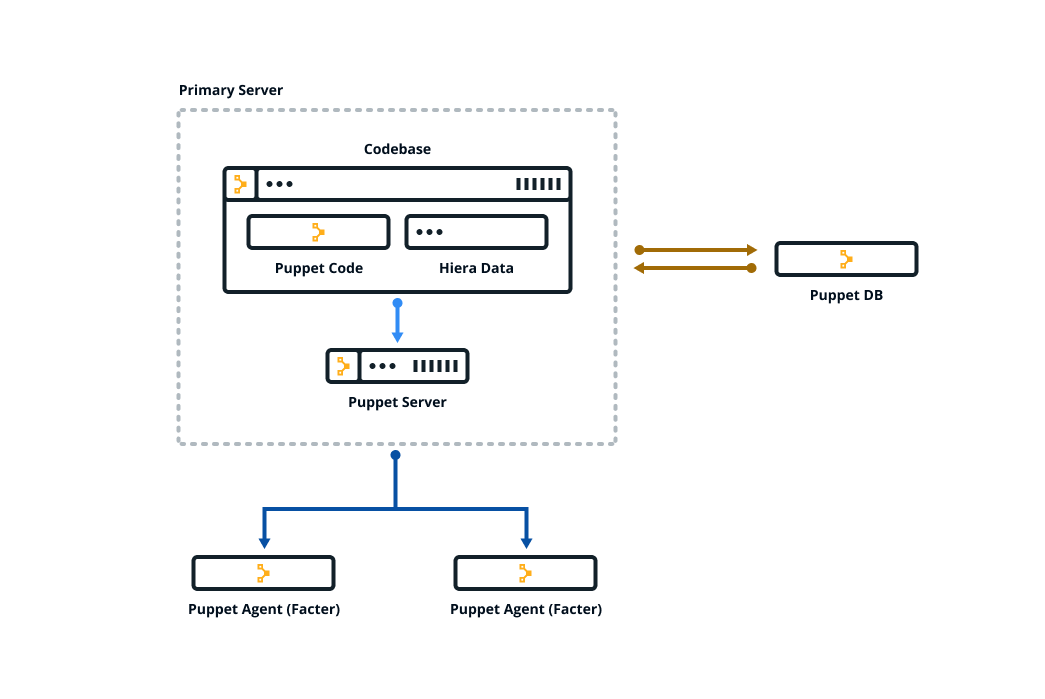
Puppet is configured in an agent-server architecture, in which a primary node (system) controls configuration information for one or more managed agent nodes. Servers and agents communicate by HTTPS using SSL certificates. Puppet includes a built-in certificate authority for managing certificates. Puppet Server performs the role of the primary node and also runs an agent to configure itself.
Facter, Puppet’s inventory tool, gathers facts about an agent node such as its hostname, IP address, and operating system. The agent sends these facts to the primary server in the form of a special Puppet code file called a manifest. This is the information the primary server uses to compile a catalog — a JSON document describing the desired state of a specific agent node. Each agent requests and receives its own individual catalog and then enforces that desired state on the node it's running on. In this way, Puppet applies changes all across your infrastructure, ensuring that each node matches the state you defined with your Puppet code. The agent sends a report back to the primary server.
You keep nearly all of your Puppet code, such as manifests, in modules. Each module manages a specific task in your infrastructure, such as installing and configuring a piece of software. Modules contain both code and data. The data is what allows you to customize your configuration. Using a tool called Hiera, you can separate the data from the code and place it in a centralized location. This allows you to specify guardrails and define known parameters and variations, so that your code is fully testable and you can validate all the edge cases of your parameters. If you have just joined an existing team that uses Puppet, take a look at how they organize their Hiera data.
All of the data generated by Puppet (for example facts, catalogs, reports) is stored in the Puppet database (PuppetDB). Storing data in PuppetDB allows Puppet to work faster and provides an API for other applications to access Puppet's collected data. Once PuppetDB is full of your data, it becomes a great tool for infrastructure discovery, compliance reporting, vulnerability assessment, and more. You perform all of these tasks with PuppetDB queries.
The diagram below shows how the Puppet components fit together.
Open source Puppet vs Puppet Enterprise (PE)
Puppet Enterprise (PE) is the commercial version of Puppet and is built on top of the Puppet platform. Both products allow you to manage the configuration of thousands of nodes. Open source Puppet does this with desired state management. PE provides an imperative, as well as declarative, approach to infrastructure automation.
If you have a complex or large infrastructure that is used and managed by multiple teams, PE is a more suitable option, as it provides a graphical user interface, point-and-click code deployment strategies, continuous testing and integration, and the ability to predict the impact of code changes before deployment.
For more information on the differences between open source Puppet and PE, see our comparison page. For additional information on PE, see the PE documentation.
The Puppet ecosystem
Alongside Puppet the configuration tool, there are additional Puppet tools and resources to help you use and be successful. These make up the Puppet ecosystem
Install existing modules from Puppet Forge
Modules manage a specific technology in your infrastructure and serve as the basic building blocks of Puppet desired state management. On the Puppet Forge, there is a module to manage almost any part of your infrastructure. Whether you want to manage packages or patch operating systems, a module is already set up for you. See each module’s README for installation instructions, usage, and code examples.
When using an existing module from the Forge, most of the Puppet code is written for you. You just need to install the module and its dependencies and write a small amount of code (known as a profile) to tie things together. Take a look at our Getting started with PE guide to see an example of writing a profile for an existing module. For more information about existing modules, see the module fundamentals documentation and Puppet Forge.
Develop existing or new modules with Puppet Development Kit (PDK)
You can write your own Puppet code and modules using Puppet Development Kit (PDK), which is a framework to successfully build, test and validate your modules. Note that most Puppet users won’t have to write full Puppet code at all, though you can if you want to. For installation instructions and more information, see the PDK documentation.
Write Puppet code with the VSCode extension
The Puppet VSCode extension makes writing and managing Puppet code easier and ensures your code is high quality. Its features include Puppet DSL intellisense, linting, and built-in commands. You can use the extension with Windows, Linux, or macOS. For installation instructions and a full list of features, see the Puppet VSCode extension documentation.
Run acceptance tests with Litmus
Litmus is a command line tool that allows you to run acceptance tests against Puppet modules for a variety of operating systems and deployment scenarios. Acceptance tests validate that your code does what you intend it to do. For more information, see the Litmus documentation.
Use cases
Puppet Forge has existing modules and code examples that assist with automating the following use cases:
- Base system configuration
- Manage web servers
-
Manage database systems
- Including Oracle, Microsoft SQL Server, MySQL, PostgreSQL
-
Manage middleware/application systems
- Including Java, WebLogic/Fusion, IBM MQ, IBM IIB, RabbitMQ, ActiveMQ, Redis, ElasticSearch
- Source control
- Monitoring
-
Patch management
- OS patching on Enterprise Linux, Debian, SLES, Ubuntu, Windows
-
Package management
- Linux: Puppet integrates directly with native package managers
- Windows: Use Puppet to install software directly on Windows, or integrate with Chocolatey
-
Containers and cloud native
- Including Docker, Kubernetes, Terraform, OpenShift
-
Networking
- Including Cisco Catalyst, Cisco Nexus, F5, Palo Alto, Barracuda
-
Secrets management
- Including Hashicorp Vault, CyberArk Conjur, Azure Key Vault, Consul Data
See each module’s README for installation, usage, and code examples.
If you don’t see your use case listed above, have a look at the following list to see what else we might be able to help you with:
-
Continuous integration and delivery of Puppet
code
- Continuous Delivery for Puppet Enterprise (PE) offers a prescriptive workflow to test and deploy Puppet code across environments. To harness the full power of PE, you need a robust system for testing and deploying your Puppet code. Continuous Delivery for PE offers prescriptive, customizable work flows and intuitive tools for Puppet code testing, deployment, and impact analysis — so you know how code changes will affect your infrastructure before you deploy them — helping you ship changes and additions with speed and confidence. For more information, see CD4PE.
-
Incident remediation
- If you need to minimize the risk of external attacks and data breaches by increasing your visibility into the vulnerabilities across your infrastructure, take a look at Puppet Remediate. With Remediate, you can eliminate the repetitive and error-prone steps of manual data handovers between teams. For more information, see Puppet Remediate.
-
Integrate Puppet into your existing
workflows
- Take a look at our integrations with other technology, including Splunk and VMware vRA.