Glossary
Definitions of terms used in Puppet documentation
abstract data type
agent
- The agent software package, also known as
puppet-agent. Puppet is usually deployed in a client-server arrangement. When you install Puppet on a device, you’re installing the agent software and its associated tools and dependencies. On *nix systems, this package is calledpuppet-agent. - The
puppet agentdaemon. You can invoke the agent software by running thepuppet agentcommand, or you can let it run in the background as a daemon. - A node that is running the agent software. By association, a node running the agent daemon can be referred to as an agent node, or an agent.
attribute
vim)
would have an ensure attribute, whose value could be
present, latest, absent, or a version
number:package {'vim':
ensure => present,
provider => apt,
}=> operator, and pairs of
attributes and values are separated by commas.catalog
A catalog is a file that describes the desired state of each managed resource on a node. It is a compilation of all the resources that the Puppet agent applies to a given node, as well as the relationships between those resources.
Catalogs are compiled by a primary server from manifests and agent-provided data (such as facts, certificates, and an environment if one is provided), as well as optional external data (such as data from an external node classifier, exported resources, and functions). The primary server then serves the compiled catalog to the agent when requested.
Unlike the manifests from which they were compiled, catalogs don't contain any conditional logic or functions. They are unambiguous, relevant to only a specific node, and generated by a node.
For detailed information, see the Catalog compilation page in the Puppet documentation.
class
A class is a collection of related resources that, after it's defined, can be declared as a single unit. For example, a class can contain all of the resources (such as files, settings, modules, and scripts) needed to configure the Apache webserver on a host. Classes can also declare other classes. For more information, see the Classes page in the Puppet language reference.
Classes are singletons and can be applied only one time in a given
configuration; although the include function allows you to declare a
class multiple times, Puppet evaluates it only one time.
The require and contain functions can create
relationships between classes. For more information, see the Containment of resources page in the Puppet
language reference.
classify
(or node classification)
To assign classes to a node, as well as provide any data required by the classes, you classify the node.
By writing a class, you enable a set of configurations. By classifying a node with the class, you describe the node's desired configuration.
You can classify nodes through node definitions in the main manifest, or with the Puppet Enterprise node manager or an external node classifier.
compile
console
core data type
(or concrete data type)
See type (data).
data type
declare
To direct Puppet to include a given class or resource in a
given configuration, you declare it using the Puppet language.
To declare classes, use a function (such as include) or
the class {'my_class':} syntax. To declare resources, use the lowercase
file {'/tmp/my_file':} syntax.
You can configure a resource or class when you declare it by including attribute-value pairs.
For more information, see Declaring classes and Resources. Contrast with define.
define
- verb: To specify the contents and behavior of a class or a defined type, you define it using the Puppet language. Defining a class or type doesn't automatically include it in a configuration; it simply makes it available to be declared.
- noun: an older term for a defined type. For instance, a module might refer to its available defines.
-
keyword: You use the
definePuppet language keyword to create a defined type.
For more information, see Defined types.
defined type
(or defined resource type)
See type (defined).
design pattern
environment
An environment is an isolated group of agent nodes that a primary server can serve with its own main manifest and set of modules. For example, you can use environments to set up scratch nodes for testing before rolling out changes to production, or to divide a site by types of hardware.
For more information, see About environments.
exported resource
An exported resource is a resource that you've declared to be available to other nodes that can then collect the exported resource and manage their own copies. This lets you share a resource's desired state across nodes, such as when one node depends on information on another node for its configuration, or when you need to monitor a resource's state.
For more information, see Exported resources.
expression
external node classifier
An external node classifier (ENC) is an executable script that returns information about which classes to apply to a node when called by a primary server. For example, Puppet Enterprise acts as an ENC.
ENCs provide an alternative to using a site's main manifest to classify nodes. An ENC can be written in any language, and can use information from any data source (such as an LDAP database) when classifying nodes.
An ENC is called with the name of the node to be classified as an argument, and returns a YAML document describing the node. For more information, see Classifying nodes.
fact
A fact is a piece of information about a node, such as its hostname, IP address, or operating system.
Facter reads facts from a node and makes them available to Puppet. You can extend Facter with custom facts, which can expose site-specific details of your systems to your Puppet manifests. For more information, see Custom facts.
Facter
Facter is the Puppet system inventory tool. Facter reads facts about a node, such as its hostname, IP address, and operating system, and makes them available to Puppet.
Facter includes many built-in facts, and you can view their names and values
for a particular node by running facter on the node's command line.
In agent-server Puppet arrangements, agents send their nodes' facts to the primary server.
For more information, see the Facter documentation.
filebucket
A repository in which Puppet stores file backups when it has to replace files is called a filebucket.
A filebucket can be local (and owned by the node being managed) or site-global (and owned by the primary server). Typically, a single filebucket is defined for a network and is used as the default backup location. For more information, see filebucket type.
function
A function is a Puppet language statement that returns a value or modifies a catalog. Puppet has many built-in functions, and modules can add their own functions. You can also write custom functions.
Functions generally take at least one value as an argument, execute Puppet code, and return a value. Because Puppet evaluates functions during compilation, the primary server executes them in an agent-server arrangement. Puppet functions can only access the facts that an agent submitted.
Contrast with lambda.
global scope
Hiera
host
- Any device, physical or virtual, attached to a network is a host. In the Puppet documentation, this can also refer to a device running the agent daemon. See also node.
-
resource type: A host can refer to an entry in a system's
hostsfile, used for name resolution. Puppet includes a type module to manage hosts. For more information, see the Host core module on the Forge.
idempotent
Idempotence refers to the concept of doing something multiple times with the same outcome. Puppet resources are idempotent, because they describe a desired final state rather than a series of steps to follow.
The most prominent exception among Puppet resources is the
exec resource type, which is idempotent but relies on the user to
design them accordingly.
inheritance
inherits keyword. The derived class declares all of the
same resources, but can override some of their attributes and add
new resources. Use inheritance very sparingly. For more information, see Classes.lambda
(or code block)
A lambda is a block of parameterized Puppet language code that you can pass to certain functions. For more information, see Lambdas.
local scope
main manifest
(or site manifest)
The main manifest is the main point-of-entry manifest used by a primary server when compiling a catalog.
The main, or site, manifest file is usually named site.pp.
Its location is set with the manifest setting in
environment.conf, with a default location set by the
default_manifest setting in puppet.conf.
For more information, see Main manifest directory.
manifest
(or Puppet code)
.pp file extension. The Puppet code in a manifest can: - Declare resources and classes.
- Set variables.
- Evaluate functions.
- Define classes, defined types, functions, and nodes.
Most manifests are contained in modules. Every manifest in a module defines a single class, defined type, or function.
The primary server service reads an environment's main manifest. This manifest usually defines nodes, so that each managed agent receives a unique catalog.
See also main manifest.
manifest ordering
Primary server
(or Primary Puppet server)
In a standard Puppet client-server deployment, the server is known as the primary server. The primary server compiles and serves configuration catalogs on demand to agents on client nodes.
The primary server provides catalogs to agents using an HTTP server. It can run as a standalone daemon with a built-in web server, or, especially if you're managing more than 10 nodes, as part of Puppet Server.
For more information, see Overview of Puppet's architecture.
serverless
metaparameter
module
A module is a collection of classes, resource types, files, functions, and templates, organized around a particular purpose. For example, a module can configure an Apache web server instance or Rails application. There are many modules available for download in the Puppet Forge.
For more information, see Module fundamentals and Installing modules.
namevar
(or name)
The namevar attribute represents a resource's unique identity
on the target system. For example, two different files cannot have the same
path, and two different services cannot have the same
name.
Every resource type has a designated namevar, usually name.
Some types, such as file or exec, have their own (in
these cases, path and command, respectively). If a
type's namevar is something other than name, it's mentioned in the type
reference documentation.
If you don't specify a value for a resource's namevar when you declare it, it defaults to that resource's title.
no-op
(or noop)
By running Puppet in no-op mode
(noop in code, short for "no operations" mode), you simulate what
Puppet will do without actually changing anything.
No-op mode allows you to perform a dry run that logs planned activity but doesn't affect
any nodes. To run Puppet in no-op mode, run
puppet agent or puppet apply with the
--noop flag.
node
A node is a device managed by Puppet. Some nodes are primary servs, which compile manifests into catalogs; most nodes, including most primary servers, are agents, which receive catalogs and apply them to the node during a Puppet run. Most nodes are computers (such as workstations and servers), but some aren't (such as supported network switches and storage appliances).
A node is also one of the fundamental units of a puppetized infrastructure. See also classify, node definition, and scope.
node definition
(or node statement)
A node definition is a collection of classes,
resources, and variables in a manifest that
are only applied to a certain agent node. Node definitions begin with the
node keyword, and can match a node by full name or regular
expression.
When a node retrieves or compiles its catalog, it receives the contents of a single matching node statement as well as any classes or resources declared outside any node statement. The classes in every other node statement are hidden from that node.
For more information, see Node definitions.
node management
node run status
When Puppet manages a node during a Puppet run, it attempts bring it into compliance with its catalog. The state of the node after a run, as tracked by Puppet Enterprise, is called the node run status. The following node run statuses are possible:
- With failures
- With corrective changes
- With intentional changes
- Unchanged
When a no-op Puppet run determines that it would have modified the node during a normal Puppet run, the node run status indicates that the change would have been made (but wasn't). There are also run statuses for unresponsive or not completely configured nodes.
For more information, see Monitoring current infrastructure state in the Puppet Enterprise documentation.
node scope
notification
notify metaparameter or the wavy
chaining arrow ~>. For more information, see Relationships and ordering.ordering
By ordering resources, you determine which resources are managed before others.
By default, Puppet uses manifest ordering, which evaluates resources in the order they're declared in their manifests. Puppet also obeys relationships you provide that determine whether a resource depends on other resources. For more information, see Relationships and ordering.
parameter
A parameter is a chunk of information that a class or resource can accept.
- In custom type and provider development: A parameter does not call a method on a provider. They are eventually expressed as attributes in instances of this resource type. For more information, see Custom types development.
-
In defined types and parameterized classes: A parameter is a
variable in the definition of a class or
defined type, whose value is set by a resource
attribute when an instance of that type or class is
declared.
define my_new_type ($my_parameter) { file { "$title": ensure => file, content => $my_parameter, } } my_new_type { '/tmp/test_file': my_parameter => "This text will become the content of the file.", }The parameters you use when defining a type or class define the attributes available when the type or class is declared.
- For external nodes: A parameter is a top-scope variable set by an external node classifier. Although these are called parameters, they are just normal variables; the name refers to how they are usually used to configure the behavior of classes.
plug-in
plusignment operator
+> adds values to resource attributes using
the plusignment syntax. This is useful when you want to override resource attributes without
having to specify already declared values a second time. For more information, see the
section about appending to resource attributes in Classes.profile
In the roles and profiles pattern of Puppet code development, a profile represents the configuration of a technology stack for a site, and typically consists of one or more classes. A role can include as many profiles as required to define itself. Profiles are included in role and profile modules.
For more information, see The roles and profiles method in the Puppet Enterprise documentation.
property
In custom type and provider development, a property is a value that corresponds to an observable part of the target node's state. When retrieving a resource's state, a property calls the specified method on the provider, which reads the state from the system. If the current state does not match the specified state, the provider changes it.
Properties appear as attributes when declaring instances of this resource type. For more information, see Custom types development.
provider
A provider implements a resource type on a specific type of
system by using the system's own tools. The division between types and providers allows
a single resource type (such as package) to manage packages on many
different systems by using, for example, yum on Red Hat systems, dpkg and
apt on Debian-based systems, and
ports on BSD systems.
Providers are often Ruby wrappers around shell commands, and can be relatively straightforward to create.
Puppet
- The Puppet suite of automation products.
- The open source Puppet project.
- The command you run to invoke the agent daemon on a node.
- The Puppet language that you use you write manifests.
- The company, Puppet, Inc.
Puppet Enterprise
Puppet language
.pp extension. The
primary server
compiles this Puppet code into a
catalog during a Puppet run. For more information, see Puppet language overview and the rest of the Puppet language docs.Puppet run
A Puppet run is when an agent sends facts and an identifying certificate to the primary server, and requests a compiled catalog in return. The agent applies that catalog to the node by using operating system-specific providers to bring the node's properties in line with the catalog's definitions, then sends a report of logs and metrics to the primary server.
By default, a Puppet run takes place every 30 minutes, even when an agent's catalog or configuration haven't changed. For a detailed description of a Puppet run, see Agent-primary server HTTPS communications.
Puppet Server
PuppetDB
Puppetfile
puppetize
r10k
Razor
Razor is a Puppet Enterprise provisioning application that helps you discover, configure, and deploy bare-metal hardware, even if it doesn't yet have an operating system. For more information, see Provisioning with Razor in the Puppet Enterprise docs.
realize
- Use the spaceship syntax
<||> - Use the
realizefunction.
A virtually declared resource is present in the catalog but won't be applied to a system until it is realized. For more information, see Virtual resources.
refresh
A resource is refreshed when a resource it subscribes to (or which notifies it) is modified.
Different resource types do different things when they're refreshed. For instance,
services restart, mount points unmount and remount, and execs execute
if the refreshonly attribute is set.
relationship
A rule that sets the order in which resources are managed creates a relationship between those resources. For more information, see Relationships and ordering.
report
You can configure agents to send reports containing logs and metrics at the end of every Puppet run. A report processor transforms those reports into a different format and sends it to another application, location, or service.
For more information, see Puppet reports.
report processor
A report processor takes a Puppet report, transforms it to a specific format, and sends it to another application, location, or service. Puppet ships with built-in report processors, and you can write your own. For more information, see Puppet reports.
resource
A resource is a unit of configuration whose state can be managed by Puppet. Every resource has a type (such as
file, service, or user), a
title, and one or more attributes with specified
values.
Resources can be large or small, and simple or complex. They do not always directly map
to simple details on the client — they might involve spreading information across
multiple files or modifying devices. For example, a service resource
models a single service, but might involve executing an init script,
running an external command to check its status, and modifying the system's run level
configuration.
For more information about resources, see Resources.
resource declaration
A resource declaration is a fragment of Puppet code that details the desired state of a resource and instructs Puppet to manage it. This term helps to differentiate between the literal resource on a system and the specification for how to manage that resource. However, resource declarations are often referred to simply as resources.
role
In the roles and profiles pattern of Puppet coding, a role defines the business purpose that a node performs. A role typically consists of one class that can completely configure categories of nodes with profiles. Classify a node with only one role; if a node requires more than one existing role, create a new role for it.
For more information, see Roles and profiles in the Puppet Enterprise documentation.
role and profile module
A role and profile module is a Puppet module that assigns configuration data to groups of nodes based on roles and profiles. A role and profile module doesn't have any special features, but it represents an abstract, private, site-specific way to use modules to configure technology stacks and node descriptions.
For more information, see the Puppet Enterprise documentation.
scope
(or variable scope; includes local scope, node scope, and top scope)
The scope refers to an area of Puppet code that is partially isolated from other areas of code. Scopes limit the reach of variables and resource defaults. Scopes can be named (such as scopes created by class definitions) or anonymous (such as scopes created by lambdas and defined resources).
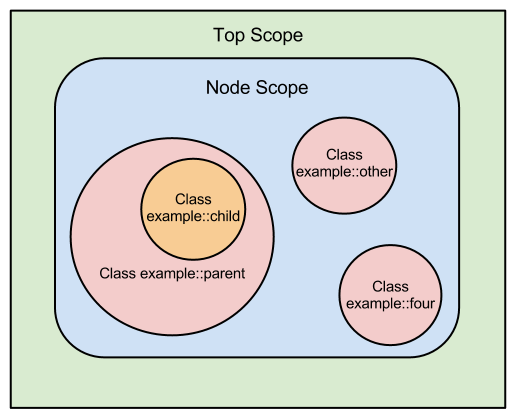
-
Top scope, from which variables are accessible from anywhere by
their short name (such as
$my_variable) but can be overridden in a local scope. The top scope's name is always an empty string, and top-scope variables can always be accessed using the double-colon namespace separator with an empty string ($::my_variable). - Node scope, a special scope created in a node definition. You can refer to a node-scope variable from anywhere within a node scope by its short name, and node-scope variables can override top-scope variables.
- Local scope, where you can refer to a variable by its short name inside that scope and the scope's children, but typically cannot access it from other scopes.
There are a few exceptions, and you might also encounter other, more situational scopes. For detailed information, see Scope.
singleton
A singleton is an object in the Puppet language, such as a class, that can be evaluated only one time. For example, you can't have more than one distinct class with the same specific name in a manifest or catalog, making that class a singleton.
site
A site refers to an entire IT ecosystem that is managed by Puppet. A site includes all your organization's primary server servers, agent nodes, serverless Puppet-managed nodes, and nodes or devices with agentless connections to Bolt or PE management.
site module
A site module is a module that contains classes
specific to a given Puppet
site. These classes describe complete configurations for a specific system
or group of systems. For example, the site::db_replica class would
describe the entire configuration of a database server, and a new database server could
be configured by applying that class to it.
subclass
A subclass is a class that inherits from another class. See inheritance.
subscribe
A subscription is a notification relationship set with the
subscribe
metaparameter or the wavy chaining arrow ~>. For more
information, see Relationships and
ordering.
template
A template is a partial document that is filled in with data from variables. Puppet can use Embedded Puppet (EPP) templates written in the Puppet language, or Embedded Ruby (ERB) templates written in Ruby, to generate configuration files tailored to an individual system. For more information, see Templates.
title
A title is the unique identifier of a resource or class in a given Puppet catalog.
- In a class, the title is the class name.
- In a resource declaration, the title is the part after the first curly
brace and before the colon. In the example below, the title is
/etc/passwd:file { '/etc/passwd': owner => 'root', group => 'root', } - In native resource types, the name or namevar uses the title as its default value if you don't explicitly specify a name.
- In a defined type or a class, the title is available for use
throughout the definition as the
$titlevariable.
Unlike the name or namevar, a resource's title needn't map to any attribute of the target system; it is only a referent. You can give a resource a single title even if its name must vary across different kinds of systems, for example a configuration file whose location differs on Solaris.
For more information on resource titles, see Resources.
top scope
See scope.
type
A type is a kind of resource that Puppet is able to manage. For example,
file, cron, and service are all
resource types. A type specifies the set of attributes that a resource of that type can
use, and models the behavior of that kind of resource on the target system. You can
declare many resources of a given type.
Puppet ships with a set of built-in resource types. See the Resource types documentation for a complete list. New native types can be added as plugins, and defined types can be constructed by grouping together resources of existing types.
Contrast with type (data). See also type (defined) and type (native).
type (data)
(or data type; includes abstract data type and core data type)
Every value has a data type, which is a named classification of a type of data that a variable or parameter can hold. The Puppet language has core data types (such as integer, Boolean, or string) and abstract data types (such as any or optional). For more information, see Values and data types.
type (defined)
(or defined type, or defined resource type; sometimes called a define or definition)
A defined type is a resource type that is defined
as a group of other resources, written in the Puppet language,
and saved in a manifest. For example, a defined type could use a
combination of file and exec resources to configure
and populate a Git repository.
After you define a type, new resources of that type can be declared just like any native or custom resource; these are called defined resources.
Because defined types are written in the Puppet language instead of as Ruby plug-ins, they are analogous to macros in other languages. Contrast with native types.
For more information, see Defined resource types .
type (native)
(or native type, or native resource type)
A native type is a resource type that is written in Ruby. Puppet ships with a set of built-in native types, and custom native types can be distributed as plugins in modules. For a complete list of built-in types, see Resource types.
Native types have lower-level access to the target system than defined types, and can use the system's own tools to make changes. Most native types have one or more providers that can implement the same resources on different kinds of systems.
value
In the Puppet language, a value is a piece of data which has a certain data type, or in some cases represents a literal data type. You can assign values to variables and parameters. For more information, see Values and data types.
variable
A variable is a named placeholder in a manifest that represents a value. After a variable is assigned a value, it cannot be assigned a different value within the same scope; however, other scopes can assign different values to that variable name.
Variables in Puppet are indicated with a dollar sign
($operatingsystem, also known as a short name) and assigned with
the equals sign ($operatingsystem = "Debian"). In certain scopes,
variables can also be accessed using a qualified name consisting of the scope name,
followed by a double-colon namespace separator, then the variable name; this pattern can
be repeated to drill down through multiple scopes. For example,
$apache::params::confdir represents the confdir
variable in the params subclass of the apache class.
Facts from nodes are represented as variables within Puppet manifests, and are automatically assigned before compilation begins. There are also several other pre-assigned variables. For more information, see Facts and built-in variables.
variable scoping
See scope.
virtual resource
A virtual resource is a resource that is declared in the catalog but isn't applied to a system unless it is explicitly realized.
For more information, see Virtual resources.