AWS Multi-region architectures for Puppet Enterprise
- Product and version: Puppet Enterprise 2019.8
- Document version: 1.0
- Release date: 31 August 2021
Introduction
This document augments our PE multi-region Reference Architectures publication by providing additional guidance and diagrams that are AWS specific to help organizations more clearly visualize how Puppet Enterprise will look when combined with AWS infrastructure primitives. To get value out of this document, the Multi-region Reference Architectures publication is required pre-reading and we recommend a basic understanding of AWS.
This document addresses two sections of the Multi-region Reference Architecture publication, the one which describes the two primary architectural patterns, Centralized and Federated and the one which addresses delivery across network segments. We’ll cover within these two sections: recommended services, native alternatives for delivery of variants, additional context on connectivity, and AWS specific definitions as needed.
All architectures in AWS should include the use of multiple Availability Zones (AZs) within each deployed region. The decision of how many AZs you utilize is flexible but a minimum of two is suggested to prevent locking yourself into a single point of failure.
Multi-region reference architectures
Centralized deployment
A Centralized Deployment in AWS is architecturally identical to what we define in generic terms for our PE Multi-region Reference Architectures publication. You are still required to select a region where you will host your Puppet Enterprise infrastructure and traffic from agents and users will communicate directly through region boundaries. This communication must be reliable but is resilient to increases in latency or limits on bandwidth.
When planning a deployment of this type you should first consider the relative locality of Puppet Enterprise to provide a consistent experience to the majority of your infrastructure. Once you select your Management Region (e.g. us-east-2) deploy a VPC and subnet for each availability zone so that you can deploy components of Puppet Enterprise across them to improve resilience to application failure. At minimum you should deploy compiler service across two different AZs and if you choose to leverage a replica for DR then deploy it to a separate AZ from where the primary was deployed. As usage grows you can deploy more Compilers across additional AZs to further improve resilience and performance.
In all architectures and their variants, when multiple compiler services are deployed to AWS a Network Load Balancer (NLB) should be used. We’ve found the NLB has a distribution algorithm that is effective at spreading load and easy to understand. Puppet Enterprise should additionally be the point of SSL termination to ensure encryption and component identities are maintained throughout the lifecycle of a request so it is advantageous to use an NLB since it does not require termination like other options within AWS. You are most likely to see the best distribution of traffic across compiler services if you enable cross-zone load balancing on the NLB to prevent an imbalance as a result of DNS resolution caching.
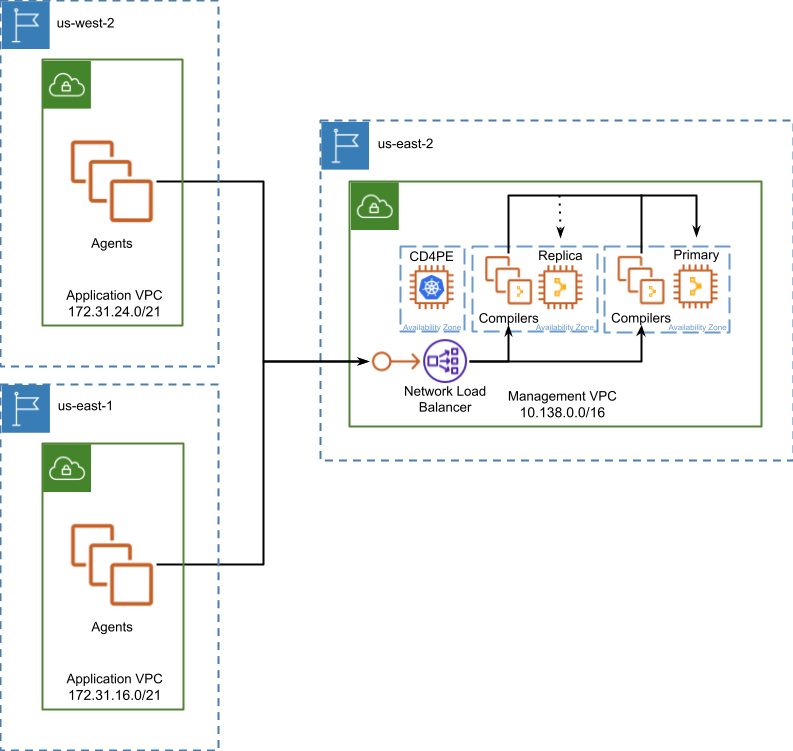
In-region proxies variation
The in-region proxies variation was created to specifically address a need by some organizations to simplify the maintenance of rules securing their Puppet Enterprise deployment in environments with strict network security policies. This simplification comes from reducing the number of IP addresses you must consider from whole network blocks to the single IP address of each proxy.
In AWS we’re able to satisfy the need for the simplification of rule sets using a native solution which is not dependent on the deployment and continued maintenance of TCP proxies. AWS adds additional value as we can build something with benefits over the original solution. For example, when building the solution upon an AWS native architecture we can ensure all traffic between Puppet Agents and our Management Region and VPC is restricted to AWS and our private networks, never traversing the public internet.
In our native solution Puppet Enterprise is registered as an Endpoint Service within your Management VPC and exposed to your Application VPC in the same region through the use of an Interface Endpoint. Each Application VPC in each region where applications are hosted gain access to this Interface Endpoint over a private IP address by implementing inter-region VPC peering to join VPC subnets together. Puppet Agents interacting with this private IP address will have their traffic bridged to an NLB. This solution enables you to configure network and firewall rules once, on the Endpoint and ensuring communication from Agents to the Puppet Enterprise deployment never traverses the public internet.
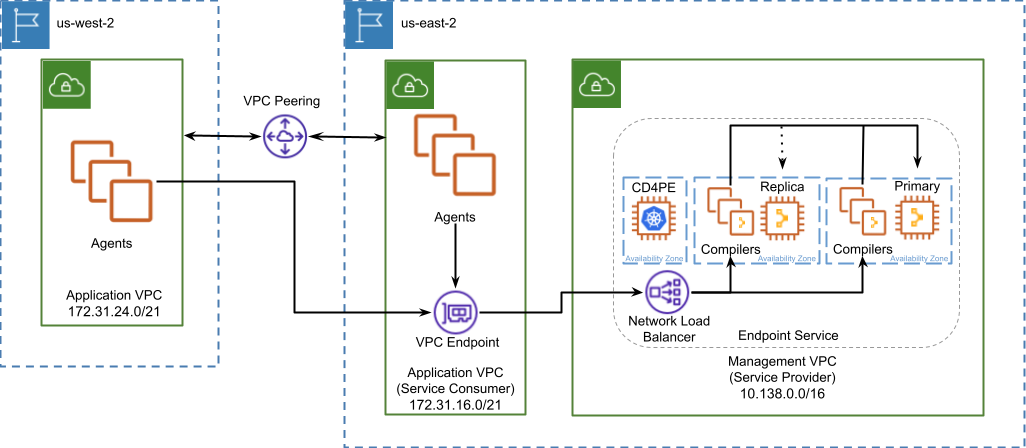
Distributed compilers variation
The distributed compilers variation that is defined as a fallback alternative to in-region proxies is ill advised in most situations in AWS. The impact that latency and bandwidth have on the communication between Compiler and primary services grows as Agent load on compiler services increases. This can lead to eventual degradation of performance under high load even between two AWS regions within the same continent and near guaranteed if compiler services must cross an ocean to communicate with the primary.
There is one scenario where this variant has limited viability, hybrid deployments which maintain Direct Connect connectivity from an on-premise data center to a specific AWS region. In this scenario distributed compiler services should be restricted to the region that is associated with the Connect Location where your Direct Connect is terminated. In this way you can provide compiler services to AWS hosted Agents in other regions similar to a vanilla Centralized deployment by choosing a Compiler region where compiler services are hosted and have a Direct Connect connection back to primary services.
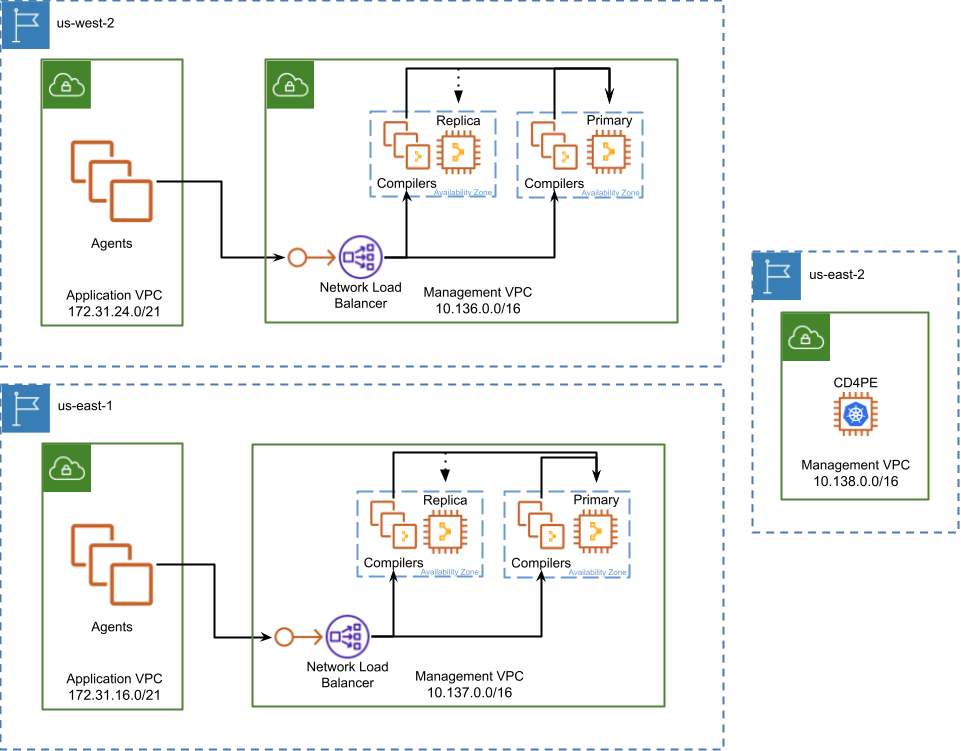
Federated deployment
A federated deployment on AWS, like the Centralized deployment is architecturally identical to what is defined within the parent publication. There is real benefit in this fact for organizations with a hybrid environment which might span several data centers of varied ages and multiple cloud providers. This makes PE deployment simpler and easier to maintain over time since it is similarly deployed everywhere.
Each region where infrastructure is hosted will have a Management VPC where an entire deployment of Puppet Enterprise, minus Continuous Delivery for Puppet Enterprise will be deployed, including a region specific NLB load balancing traffic across in-region Compiler services. The Continuous Delivery for Puppet Enterprise service is not subject to the same latency and bandwidth requirements as the rest of the PE installation, making it possible to deploy it out of region. The capability to manage code deployments from outside the region where the rest of the cluster operates makes Continuous Delivery for Puppet Enterprise ideal for orchestrating a multi-region global PE infrastructure.
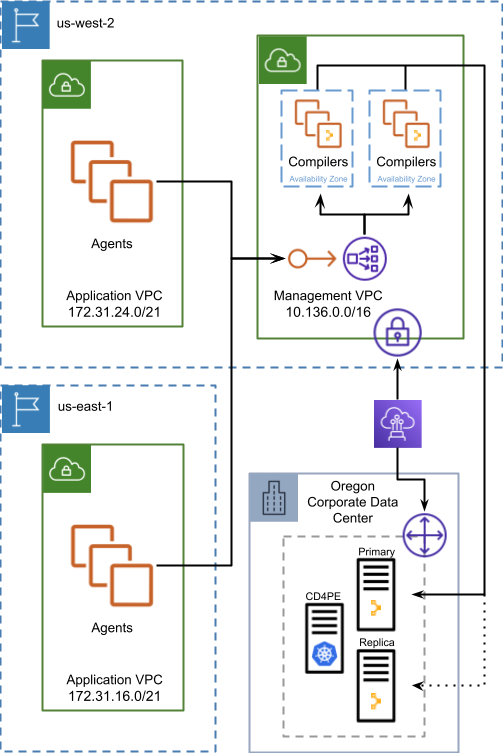
Service delivery spanning network segments
The Puppet Enterprise application architecture is built upon universal infrastructure primitives, making it adaptable across a large variety of hybrid architectures. Security and network segmentation strategies are an important part of your decision to deploy one architecture over another and they take on a heightened level of consideration when operating in AWS. The migration of applications to the cloud, Puppet Enterprise included, makes it possible to build application-specific network and security topologies which live much closer to the application than in traditional networks.
The following diagram illustrates how a federated architecture which leverages an in-region proxies variation can be composed together to provide Puppet Enterprise services across a hybrid estate.
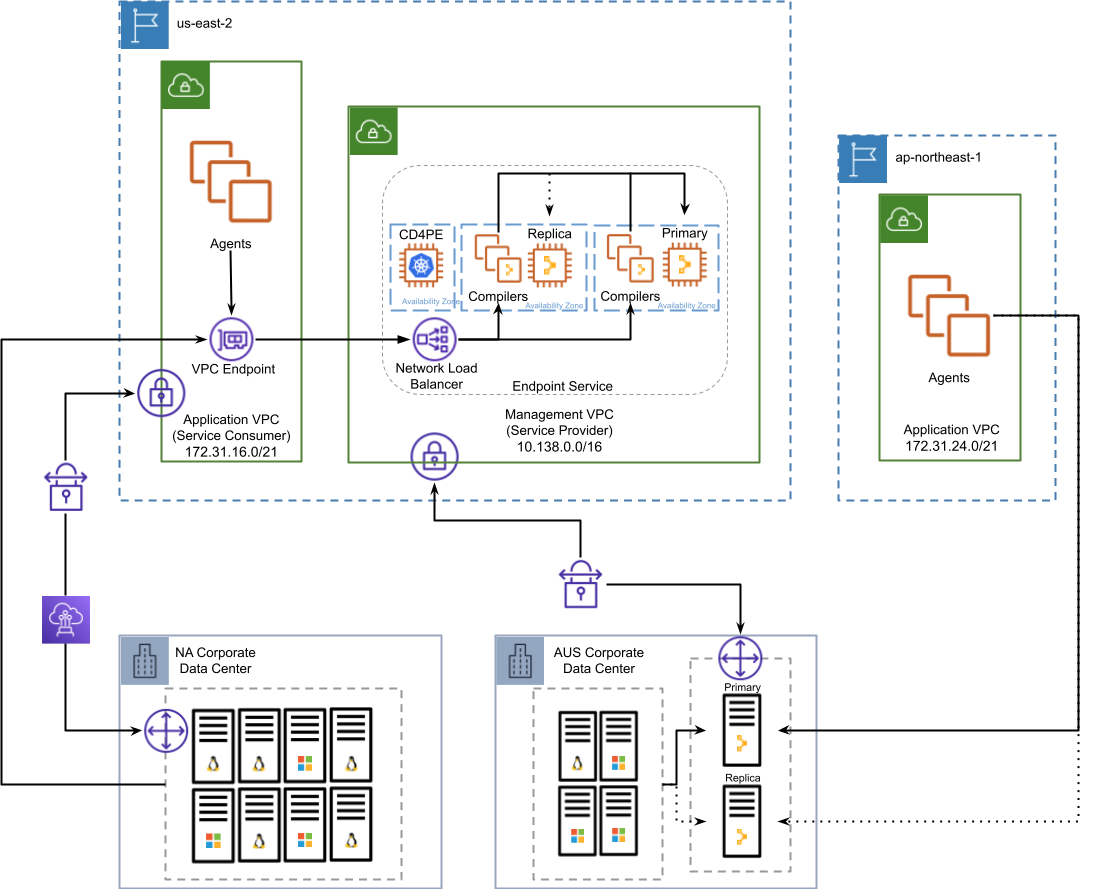
Definitions
The PE multi-region Reference Architectures publication content is consistent and valid on AWS but uses generic language without indicating how it maps to an AWS vernacular. We redefine some of them here for clarity.
Primary services must be deployed to a single availability zone and VPC
Compiler services may be deployed to multiple availability zones and VPCs
Replica services may be deployed to a single availability zone, which doesn’t need to be the same AZ where primary services are deployed to and a single VPC, which should be the same VPC where primary services are deployed
Puppet services must all be able to connect to each other according to the component and port requirements documented here. An example of the required AWS security group definition needed for internal PE communication can be found here. Emphasis should continue to be put on the importance of DNS, Puppet Enterprise in AWS still depends on it.