Continuous Delivery for Puppet Enterprise multi-region reference architectures
- Product and version: Continuous Delivery for Puppet Enterprise 4.9
- Document version: 1.2
- Updated: 6 December 2021 (first published September 2021)
Introduction
This document provides guidance for deploying Continuous Delivery for Puppet Enterprise (PE) in a multi-region scenario to achieve DR and multi-data center deployment to achieve HA. Providing guidance on definitions of HA and DR, the architecture of Continuous Delivery for PE on Puppet Application Manager (PAM), and how this is related to PE cluster connectivity.
Definitions of HA and DR
Failures are various events ranging from slowdown, interruption or complete loss of components, which affect the application deployment, network or underlying infrastructure.
HA (High availability) describes a deployment model where a defined level of failure can be tolerated without loss or interruption of service, although there is likely to be a reduced capacity.
DR (Disaster recovery) describes a deployment model where failures will cause a loss of service but can be responded to with a defined recovery plan to restore service within an accepted time frame (RTO) and with an accepted time frame of data loss (RPO)
Definitions of region and multi-region vs multi-data centre
A region is a set of data centres interconnected with low latency connections in a geographical location.
A multi-region deployment creates resilience for geographical issue affecting multiple data centres or a whole region by deploying across regions.
A multi-data centre deployment creates resilience for data centre issues by deploying across data centres in a single region but would still be vulnerable to the underlying region failing.
Multi-region DR
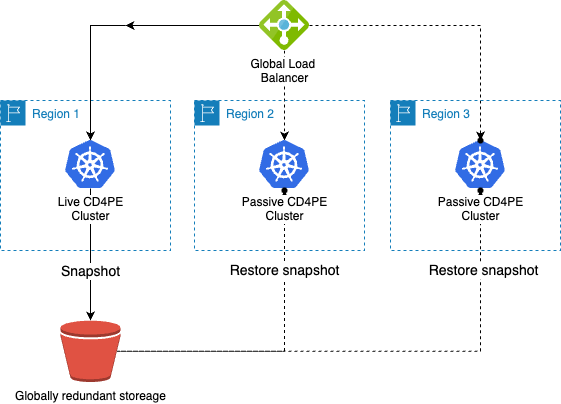
In a multi-region model, snapshots are taken from Continuous Delivery for PE running in the live region and made available to storage which is available to the DR region(s). In the event of a failure in the live region, the snapshot would be restored to a Continuous Delivery for PE cluster in one of the DR regions and a global load balancer would ensure all traffic was directed to newly live region.
DR with globally redundant storage
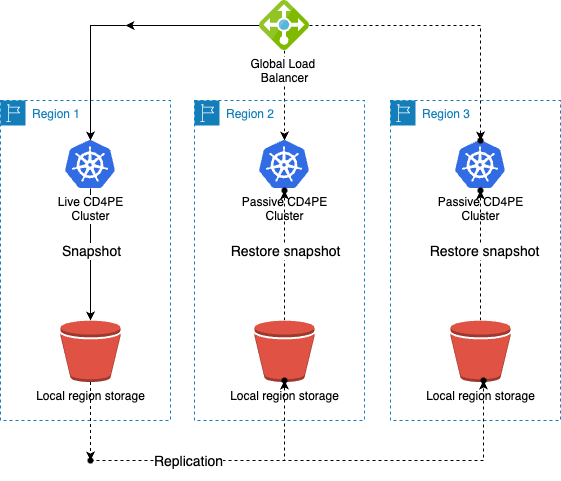
DR with replicated redundant storage
The key components are described in detail below.
Global storage
The implementation of this global storage will very much depend on the underlying cloud, each cloud vendor has approached region redundancy differently for storage. The key configuration point is that PAM can only backup to a single location as per the PAM snapshots, the storage location therefore must be globally redundant or copies would have to be made with replication to make the snapshot available in other regions.
Global addressing
A global load balancer with regional redundancy should be available to ensure that when a regional failure happens any traffic directed to Continuous Delivery for PE will be redirected to the restored DR region.
Snapshots
A least a single recovery point of a full snapshot should be kept and regularly scheduled as per the PAM snapshot guide.
Restoring
During a region failure a restore of a snapshot will be performed as per PAM snapshot restore guide. It will be a choice related to the required RPO as to how regularly the snapshot should be scheduled and a choice based on RTO as to whether the cluster in DR regions is built in advance of the event.
RTO/RPO
Two of the key aspects to consider in the design choices above will be RTO and RPO.
The RTO (Recovery time objective) is a measure of how long it will take to restore Continuous Delivery for PE from failure to normal service. This is going to depend on the size of the snapshot created, the configuration of instances/storage used and whether the target region clusters are pre-provisioned. Confirming the RTO with a practice DR event would be advised
The RPO (Recovery point objective) is how much data can be lost (measured in time) which will be defined by the schedule of the snapshots.
Multi-DC reference architecture for HA
Design considerations for Kubernetes
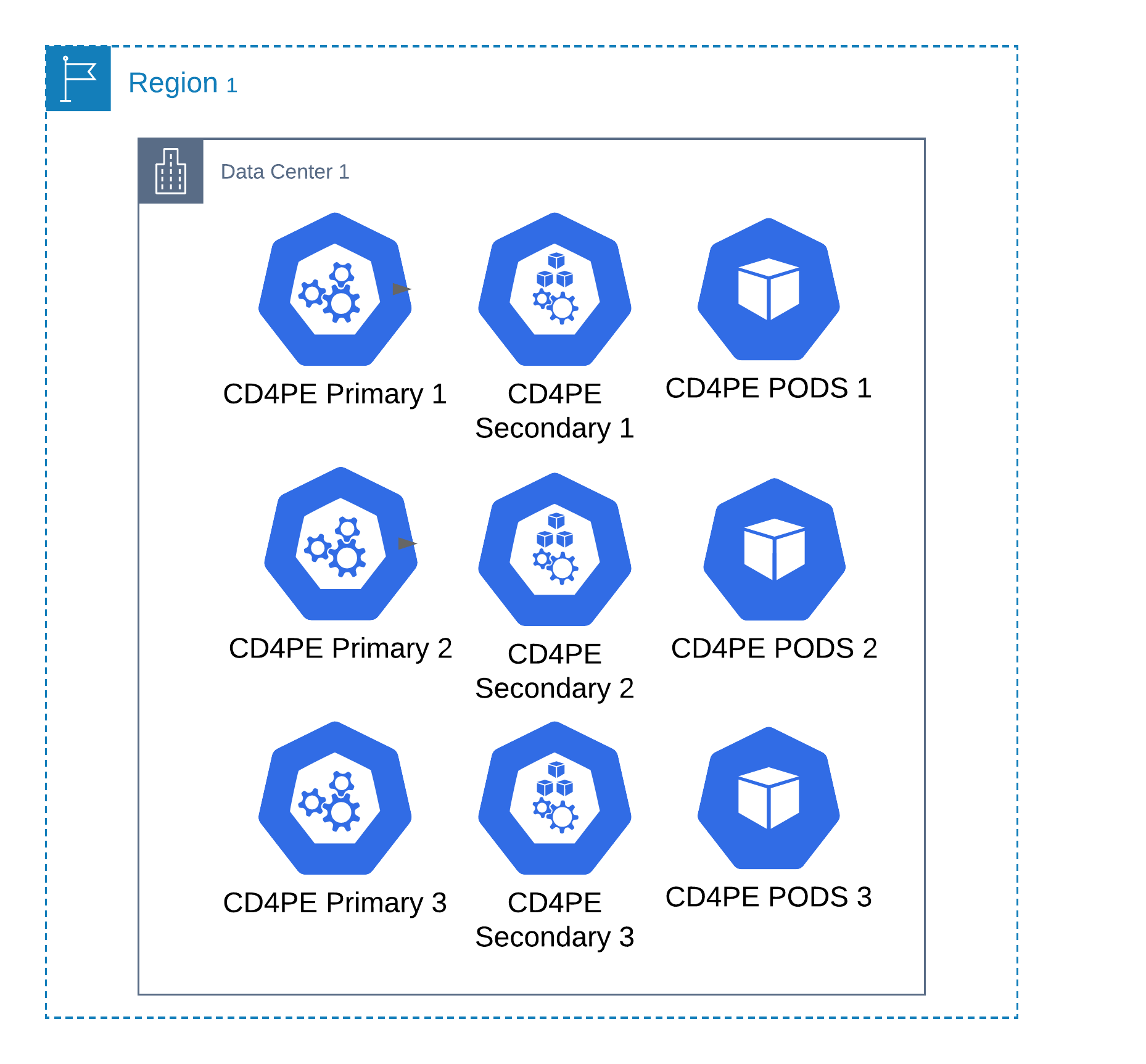
Continuous Delivery for PE v4 is deployed via PAM built on KOTS (kubernetes-off-the-shelf). These deployments contains primary nodes, secondary nodes and PODS.
Primary nodes runs core Kubernetes components (referred to as the Kubernetes control plane) as well as application workload.
Secondary nodes runs application workloads. These are also sometimes referred to as workers.
Pods are a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers.
To achieve HA there must be a least three primary nodes which would allow for the failure of one primary node and consideration must be given to the capacity requirements with failures of secondary nodes.
The core limitation of this configuration is due to the nature of k8s as per kubernetes documentation, kubernetes can't be setup across regions preventing any Multi Region HA setup.
A full software architecture overview of Continuous Delivery for PE is documented here and reference architectures for deploying Continuous Delivery for PE are documented here
Single region HA
This section will cover the multi data centre options to achieve HA within a single region.
Single data centre
In a single data centre we can deploy a HA PAM setup which will cope with individual node failures but Continuous Delivery for PE will fail if the data centre it resides in has a failure.
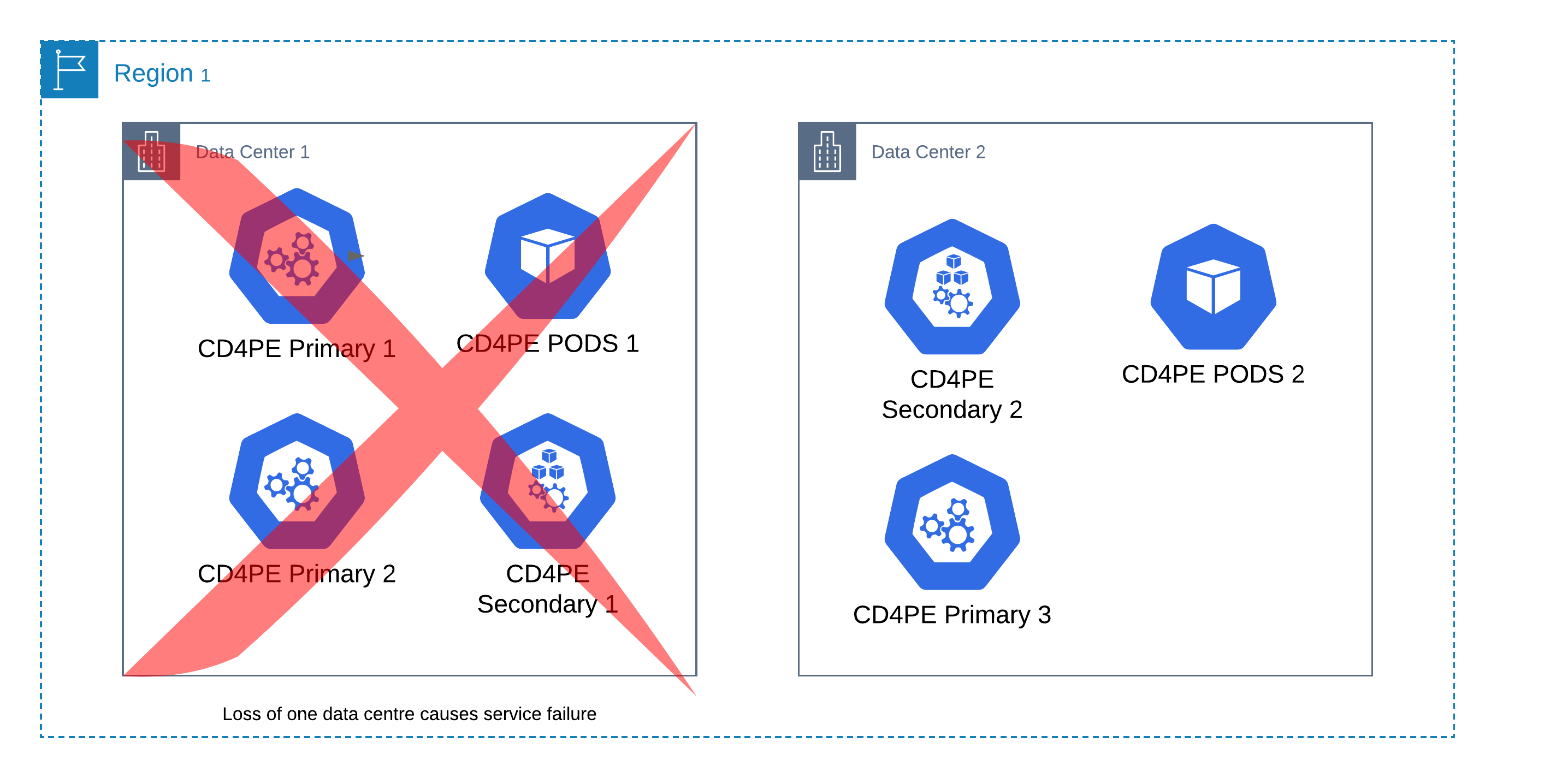
Two data centres
Although a common pattern, a two data centre deployment we will not gain any benefit over a single data centre as a failure on the data centre carrying the two primaries will cause a failure to the whole cluster.
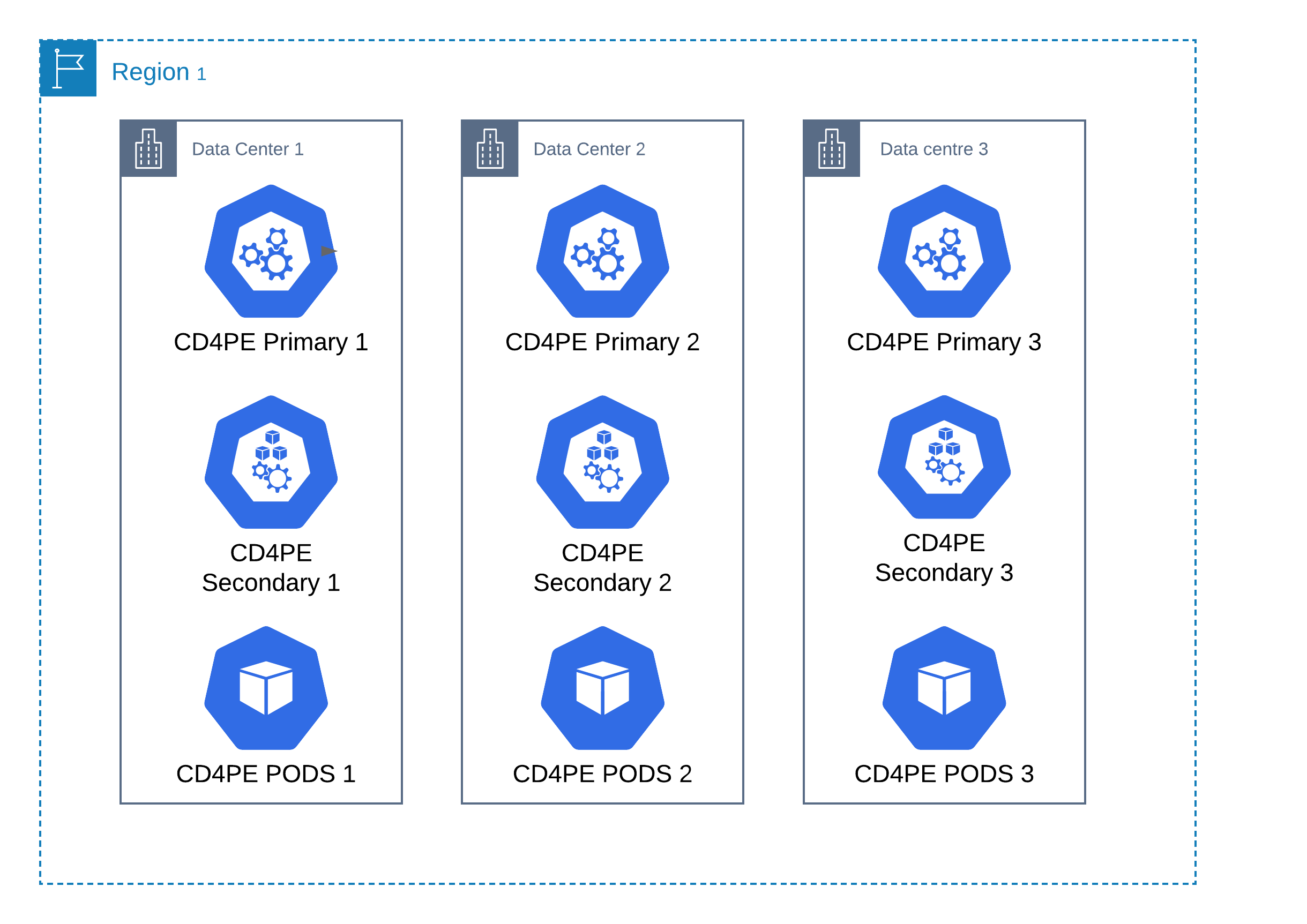
Three data centres
A three data centre setup is the recommend approach to HA in a single region, a failure of a data centre will reduce capacity for workload but will not affect service.
PE Clusters connectivity
PE clusters connecting to Continuous Delivery for PE in any of these setups have no requirements to be in the same region or Data centre as long as appropriate ports and connectivity are available.